
首个复数大模型!北大推出 2 比特超低比特量化新方案。
当前,大模型在推理过程中往往面临巨大的存储与计算开销,主要原因在于模型权重普遍采用 FP16 格式存储,占用大量空间。
北京大学研究团队首次提出 iFairy 方案,将模型权重量化至复数集合 {+1, -1, +i, -i}。
这四个数值恰好可用 2 比特进行编码,相当于将原始存储需求压缩至 1/8。
在推理阶段,复数与 {±1, ±i} 的乘法运算无需实际执行乘法操作,仅通过加减或数据位置交换即可完成,极大降低了计算开销。
不仅如此,研究团队还对整个 Transformer 架构进行了全面“复数化”重构。
实验结果显示,iFairy 模型在语言建模困惑度(PPL)上显著优于全精度(FP16)的 LLaMA 基座模型,降幅高达 10%,在多项下游任务中表现甚至反超原始全精度模型,为 GPT-5 级别大模型在手机等终端设备上的部署提供了可行性。
目前,该项目的论文、代码、模型权重及实验脚本已全部开源,支持完整复现训练流程。
核心突破:极致压缩与全新量化机制 PhaseQuant
为提升模型性能,业界普遍依赖增加参数规模,导致部署成本居高不下。
同时,庞大的参数量带来计算负担激增。尽管已有如 MXFP4 等量化方案出现,但其核心仍依赖高成本的“乘法”运算,难以从根本上降低推理延迟。
北大团队提出的 iFairy 方案成功打破这一瓶颈。
模型体积压缩至原模型 1/8
在“空间”层面,iFairy 实现了极致压缩。
传统 FP16 权重需 16 比特表示,而 iFairy 仅用 2 比特即可完成权重编码。
这意味着相比标准 FP16 模型,模型体积缩减为原来的 1/8。如此高的压缩率,为大模型在手机、车载设备等边缘场景的部署扫清了存储障碍。
PhaseQuant:实现“无乘法”计算
在“时间”维度,团队提出全新量化算法 PhaseQuant,使 iFairy 实现“无乘法”推理。
PhaseQuant 算法详解
该成果的核心在于 PhaseQuant 算法。不同于传统将权重映射到实数域的方法,PhaseQuant 基于参数的相位信息,将其投影到复平面上的四个单位根 {+1, -1, +i, -i}。
△PhaseQuant 量化算法示意图
这一设计带来多重优势:
信息密度:使用 {+1, -1, +i, -i} 四个值,充分利用了 2-bit 的全部编码能力,信息熵从传统三值量化(如 BitNet 的 log3≈1.58-bit)提升至满格的 log4=2-bit。
对称性:四个点在复平面中关于原点对称,有助于保持模型训练稳定性。
稀疏性:每个量化后的复数权重,其实部或虚部必有一个为零,在高维空间中自然保留稀疏结构,利于高效计算。
“无乘法”运算机制
标准复数乘法 (a+ib)(c+id) 需要 4 次实数乘法和 2 次加法,计算开销较大。
但在 iFairy 模型中,当激活值与 {±1, ±i} 类型的权重相乘时,乘法操作被完全规避。
△超低比特复数运算规则
模型中最耗时的矩阵乘法(GEMM)被彻底重构。
原本昂贵的浮点乘法被替换为成本极低的加法、减法和数据重排(shuffle)操作,从根本上消除了计算瓶颈,为推理速度的飞跃提供了基础。
架构创新:全复数化的 Transformer 设计
研究团队进一步将整个 Transformer 架构“复数化”。
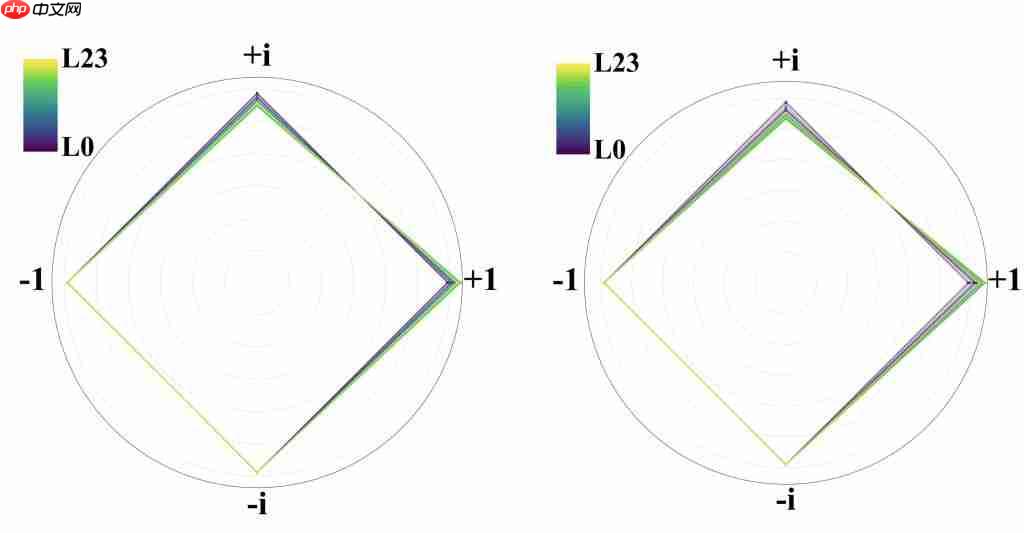
△Fairy ± i 模型主干结构
复数注意力机制:传统注意力通过 Q 和 K 的点积计算相似度,iFairy 则采用 Hermitian 内积的实部作为得分,既保留全部复数信息,又输出实数结果用于 Softmax。
复数旋转位置编码(RoPE):在复数域中,位置编码的旋转操作变得极为简洁,仅需一次复数乘法即可完成。
性能表现:PPL 下降 10%,下游任务全面超越
实验结果表明,iFairy 不仅避免了超低比特量化常见的性能崩塌,反而实现了反超。
在语言建模能力评估中,困惑度(PPL)越低,代表模型预测能力越强。测试显示,在相同训练数据下(为确保公平,所有对比模型数据一致,详见论文),2-bit 的 iFairy 模型 PPL 显著低于全精度 FP16 模型,最高降幅达 10%。
△iFairy PPL 评测结果
在下游任务中,iFairy 在多个 zero-shot 场景下的表现也超越了原始 LLaMA 基座模型。
△iFairy 下游任务评测结果(zero-shot)
对量化后权重分布的分析显示,{±1, ±i} 四个值的使用高度均衡,说明模型真正学会了利用这套复数编码系统。
△左侧为 k_proj 层参数分布,右侧为 o_proj 层参数分布
这项工作融合了复数神经网络与超低比特量化的思想,通过挖掘“相位”这一被忽视的信息维度,在不增加存储成本的前提下,显著增强了模型表达力与性能。
或许,我们距离在普通手机上运行 GPT-5 级别的大模型,已不再遥远。相关论文、训练代码、模型权重与实验脚本均已开源,涵盖训练、评测与复现全流程,人人皆可上手。
论文链接:https://www.php.cn/link/7f6667b99574125f65ba90c88d3c6cc3
huggingface 链接:
https://www.php.cn/link/7dc75483c8b2ace7420712262f0b6303
github 链接:https://www.php.cn/link/1112f0e7f3d6f7d412b1ba38bc94e6e8
一键三连「点赞」「转发」「小心心」
欢迎在评论区分享你的看法!
— 完 —
点亮星标
科技前沿进展每日见
以上就是北大提出首个复数大模型,2 比特量化,推理仅加法,可手机部署!的详细内容,更多请关注其它相关文章!





发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。