
当大数据浪潮席卷各个行业,控制理论也迎来了关键转折点:从依赖精确模型转向依赖海量数据。
然而,在数据驱动控制(datatic control)领域,长期缺乏一种统一、高效的数据表达规范。
为解决这一难题,清华大学李升波教授领导的iDLab课题组首次将经典控制理论中的“标准型”思想引入数据驱动范式,提出了一种全新的基于数据的系统描述方式——数据标准型。
每条数据样本由两部分构成:必需的转移信息与可灵活配置的属性模块,分别用于刻画系统的动态演化规律和承载人工定义的功能特征。

更进一步,这种数据结构支持根据具体算法需求定制附加属性,有效减少重复计算,显著提升控制器设计速度,为数据驱动控制的效率优化开辟了新路径。
该研究成果已被ACC2025录用发表。
从模型标准型到数据标准型人工智能的飞速发展,离不开高质量数据的支持。
近年来,随着AI技术在各领域的渗透,以数据为核心的方法逐渐进入控制系统的设计流程。
控制方法正经历一场深刻变革:从传统的模型驱动控制(modelic control),逐步迈向数据驱动控制(datatic control)。
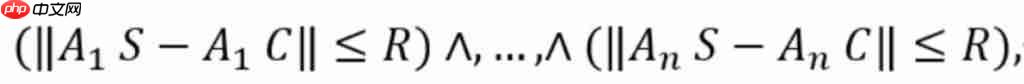
△图 1:两种控制范式的对比示意图
在模型驱动控制(上图路径)中,首先通过系统辨识建立数学模型,再基于该模型设计控制器;
而在数据驱动控制(下图路径)中,控制器直接由原始数据生成,跳过了建模环节。
在传统模型驱动框架下,“标准型”是极为重要的工具。
例如,控制理论奠基人鲁道夫·卡尔曼(Rudolf E. Kálmán)指出:若将状态空间模型表示为可控或可观标准型,则无需额外验证即可保证系统的可控性或可观性。
同样,数学家卡米耶·若尔当(Camille Jordan)提出的约旦标准型,可将系统矩阵转化为对角形式,其对角线元素即为系统特征值。
由此,仅需检查所有特征值是否具有负实部,便可快速判断系统稳定性。同时,不同特征值对应不同动态模态,有助于实现精准控制设计。
但在数据驱动控制范式中,是否存在类似的“标准型”?这是一个尚未被解答的问题。
随着机器人、自动驾驶等具身智能系统的兴起,系统交互过程中产生的数据量呈指数级增长。这些复杂、高维的数据给传统控制算法带来巨大压力,也催生了一个核心问题:
能否构建一种标准化的数据表达方式,使大规模数据能被高效利用?答案正是本研究提出的数据标准型。
数据的组织形式直接影响后续算法的效率与扩展能力。
以强化学习为例,训练过程常涉及大量迭代和高维运算,容易陷入重复计算的困境——比如每次迭代都重新计算样本间的距离或相似度。
这类冗余操作不仅耗时,还严重消耗算力资源,限制了算法在实际场景中的部署。
因此,如何对数据进行高效、规范化的组织,避免重复计算、提升运行效率,成为数据驱动控制面临的关键挑战。
受模型标准型启发,该研究首次提出适用于数据驱动系统的标准数据结构(如图2所示):
△图 2:数据标准型结构示意图
(1)转移部分:记录状态转移信息,包含系统动力学的关键数据;
(2)属性部分:可插拔模块,可根据算法需要预置奖励、特征编码等辅助信息。
前者为控制器设计提供必要基础,后者则按需启用,兼顾灵活性与存储效率,从而全面提升算法性能。
实验验证:加速近邻搜索研究人员通过一个典型应用场景展示了数据标准型的优势。
在强化学习中,许多算法依赖回放缓冲区中的样本进行策略优化,常需执行“最近邻搜索”操作——例如比较当前策略行为与历史数据之间的差异:
由于需遍历整个数据集寻找最接近的样本,计算开销极大。

AI无损放大图片
16
为此,研究团队提出一种空间属性预置机制:在数据标准型中引入一组预先设定的锚点(anchor points),并为每个样本提前计算其到各锚点的距离,作为可插拔的空间属性保存下来。
△图 3:空间属性构造示意图
基于此,研究提出了空间筛选条件定理,用于快速缩小候选样本范围。
定理 1(空间筛选条件)
设数据集中存在 n 个锚点,C 为目标样本,S 为任意其他样本。若 S 位于 C 的 R-邻域内,则必须满足以下条件:
其中 ∧ 表示逻辑与运算符。
利用该条件,只需一次判断指令即可排除大量无关样本,大幅压缩搜索空间。

△图 4:空间筛选机制示意图
实验在D4RL数据集的Hopper任务中开展,对比使用空间标准型前后的训练时间。
结果如图5所示:原始版本(蓝色曲线)耗时约20小时,而引入空间标准型后(橙色曲线),训练时间缩短至7小时,提速近三倍。
△图 5:训练时间对比图
由此可见,数据标准型以极小的存储代价,换取了显著的时间效率提升。
此外,其模块化设计允许按需启用属性字段,降低存储负担,具备良好的可扩展性,为未来数据驱动控制算法的发展提供了全新思路。
论文链接:https://www.php.cn/link/c1927a57de5c455d3bb1e6cdae59fab5
一键三连「点赞」「转发」「小心心」
欢迎在评论区分享你的看法!
— 完 —
点亮星标
科技前沿进展每日见
以上就是清华首次提出数据驱动控制新形式,算法效率直翻三倍的详细内容,更多请关注其它相关文章!





发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。