
大语言模型可以打王者荣耀了!
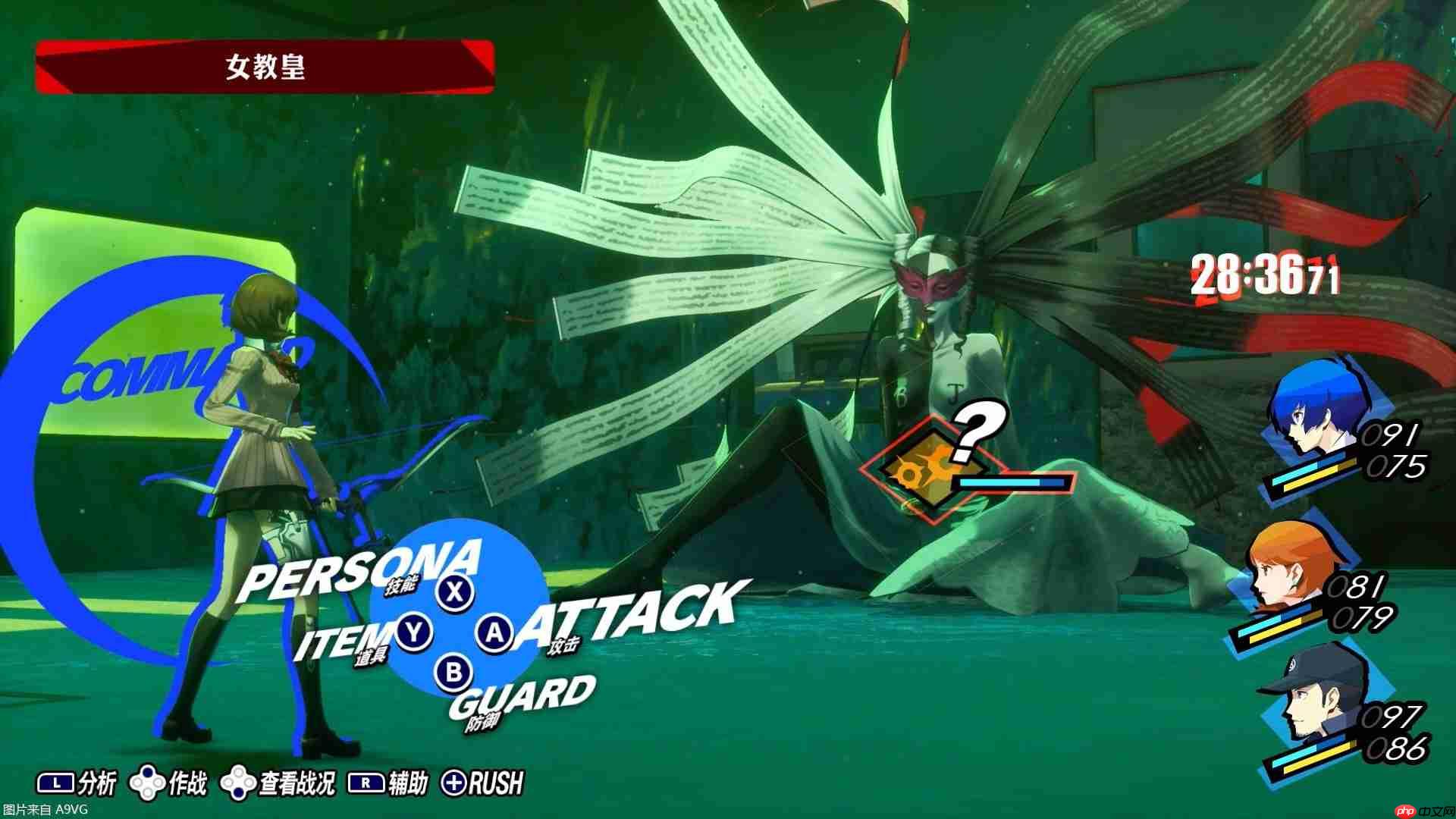
腾讯最新提出的Think-In-Games ( TiG ) 框架,直接把大模型丢进王者荣耀里训练。它不仅能实时理解盘面信息(英雄、发育、兵线、防御塔、资源、视野等),还能打出像人类玩家一样的操作。
更炸裂的是,靠着这种 " 边玩边学 " 的训练方式,让仅14B参数的 Qwen-3-14B,干翻了671B的 Deepseek-R1,动作精准度高达90.91%!
那么问题来了:它是怎么做到的?
TiG:边玩边学
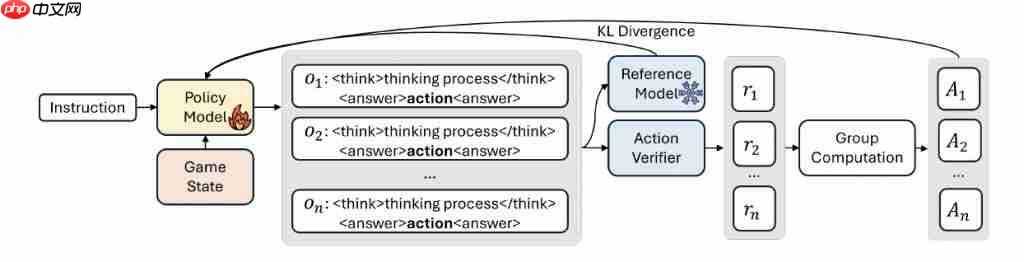
总的来说,TiG 将基于强化学习的决策重新定义为一种语言建模任务。大语言模型生成由语言指导的策略,然后根据环境反馈,通过在线强化学习进行迭代优化。
这一方法弥合了传统大语言模型只知道为什么,但无法作出行动;强化学习只知道行动,却无法解释为什么的鸿沟。
为了实现这一方法,研究团队直接让大语言模型在《王者荣耀》中行动,并解释原因。
值得注意的是,在这一框架中,大语言模型主要学习了人类玩家在《王者荣耀》游戏中宏观层面的推理能力。
与微观层面动作(如精确技能施放)不同,宏观层面推理优先考虑长期目标和团队协同,涉及制定和执行团队范围的策略,例如控制目标、地图施压和协调团队机动。
这也就意味着,与其说 TiG 是一名职业选手,不如说他是能精准判断场上局势的金牌教练。
具体来说,Tig 将决策转化为文本,模型通过读取 JSON 获取游戏状态,然后再从固定菜单(例如推进或防御)中选择宏操作(如推上路 "、" 夺龙 "、" 防守基地 "),并解释为何如此。
举例来说,在上图的游戏场景中,阿古朵,与队友姜子牙在中路推进,目标是敌方一座血量较低的一塔 。
基于此,模型先对游戏状态进行全面评估 。例如," 防御塔和野区保护机制均已失效 "(对局已进入中期)。然后分析优先目标(摧毁中路一塔),制定策略(联合姜子牙前往敌方中路一塔,集中火力推塔)并提示风险,
最后,模型将结合英雄的的理解,建议作为射手的阿古朵 " 保持安全距离输出 ",并与姜子牙的控制效果协同配合,并将这一指令输出给玩家 " 联合姜子牙推掉敌方中路一塔,注意敌方可能埋伏 "。
为了实现上面在游戏中边玩边学的效果,研究团队先从真实游戏对局中采样,构建数据集,为了确保每个游戏状态都带有一个宏观级别的动作标签,研究提出了" 重新标注算法 "。
该方法先在帧窗口内进行向后填充,再通过优先级覆盖机制确保每个状态都标注为最关键的宏观动作。这样得到的密集且一致的序列,为后续的 GRPO 训练与基于规则的奖励函数提供了稳健信号。
之后,为了在游戏环境中实现有效的战略推理学习,研究团队采用了Group Relative Policy Optimization ( GRPO ) 算法,以最大化生成内容的优势,并限制策略与参考模型之间的分歧。
在奖励设置方面,TiG 使用基于二元规则的奖励,当预测操作与人类游戏玩法匹配时为 1,否则为 0,从而保持更新的稳定性和成本。
奖励是基于实战积累的过程性知识、人类可读的战略规划,以及依然保持完好的通用语言能力。
训练过程与实验结果
TiG 采用多阶段训练方法,结合了监督微调(SFT)和强化学习(RL)来增强模型能力。

AI无损放大图片
 16
16
SFT 阶段:从 Deepseek-R1 中提取训练数据进行 SFT。这些数据展示了强大的推理能力,可以帮助较小的模型获取深度推理能力。
在线 RL 阶段:使用真实游戏数据,并利用 GRPO 算法训练模型。
在具体的实验中,研究探索了多种训练方法的组合方式。
GRPO:仅使用 GRPO 算法训练基础模型,不进行 SFT 训练。
SFT:仅使用 SFT 训练数据集训练基础模型 。
SFT + GRPO :首先使用 SFT 训练基础模型,然后应用 GRPO 算法进一步训练,以提高模型的推理能力。
(注:为了评估模型的质量,研究设置了以下不同规模的基线模型,包括 Qwen-2.5-7B-Instruct、Qwen-2.5-14B-Instruct、Qwen-2.5-32B-Instruct、Qwen-3-14B-Instruct 和 Deepseek-R1)
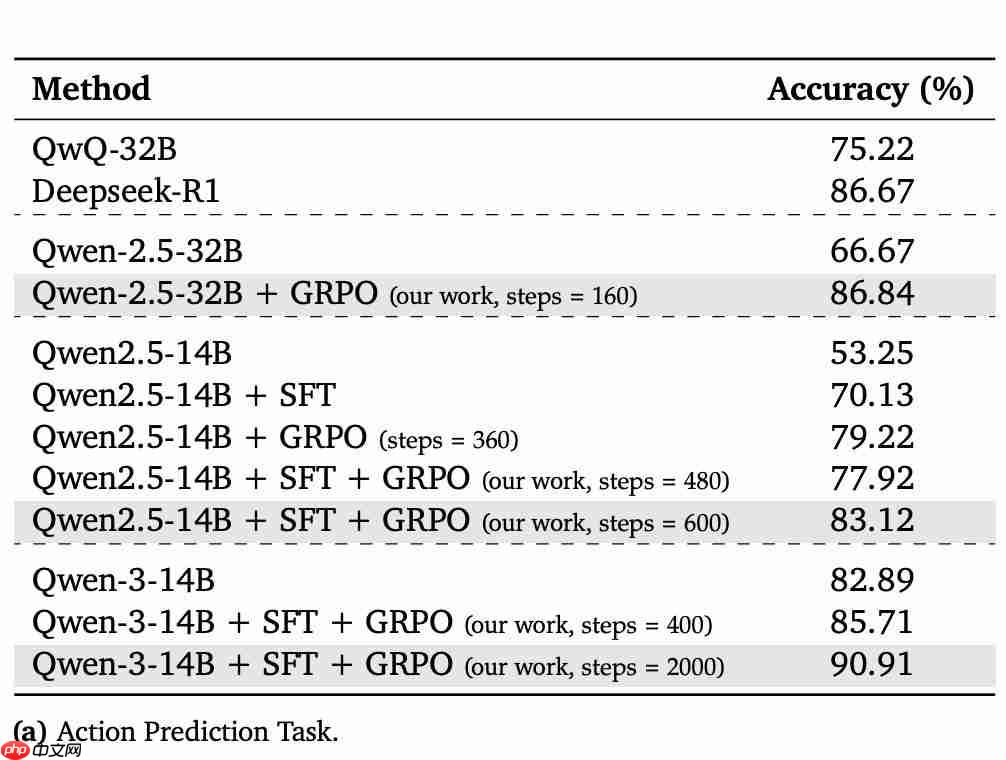
实验结果表明:SFT 和 GRPO 的组合能显著提高不同模型规模的性能,Qwen-2.5-32B 在应用 GRPO 后,准确率从 66.67% 提高到 86.84%。而 Qwen2.5-14B 在依次应用 SFT 和 GRPO 后,准确率从 53.25% 提高到 83.12%。
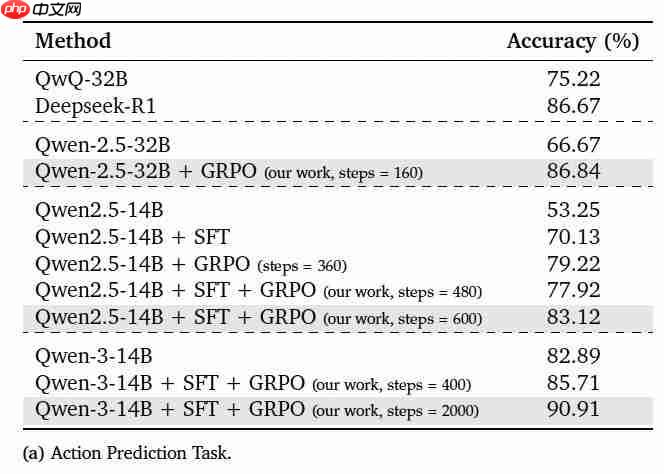
此外,正如我们开头提到的,经过 SFT 和 GRPO 训练(2000 步)的 Qwen-3-14B 达到了 90.91% 的准确率,超过了参数量大一个数量级的 Deepseek-R1(86.67%)。
综上,TiG 不仅弥合了 " 知其然 " 与 " 知其所以然 " 之间的鸿沟,还在数据量和计算需求显著降低的情况下,取得了与传统 RL 方法具有竞争力的性能。
参考链接
[ 1 ] https://arxiv.org/abs/2508.21365
[ 2 ] https://x.com/rohanpaul_ai/status/1962499431137493195
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
专属 AI 产品从业者的实名社群,只聊 AI 产品最落地的真问题 扫码添加小助手,发送「姓名 + 公司 + 职位」申请入群~
进群后,你将直接获得:
最新最专业的 AI 产品信息及分析
不定期发放的热门产品内测码
内部专属内容与专业讨论
点亮星标
科技前沿进展每日见
table{ border-collapse:collapse;/*表格边框合并*/ border:1px solid #ddd;/*表格边框风格*/ width:100%;/*表格宽度*/ margin:10px 0;/*表格外边距*/ font-size:14px;/*字体大小*/ } td,th{/*表格单元格*/ padding:10px; border:1px solid #ddd; text-align:center; } 王者荣耀相关攻略 王者荣耀朵莉亚-幻珠鲛人皮肤技能效果前瞻介绍 与好友一起战队爽!《王者荣耀世界》公布毕方BOSS实机多人战斗演示 嘻哈天王养成攻略 王者荣耀顶级加几颗星 顶级加星规则机制详细讲解 王者荣耀顶级对抗路怎么获得 顶级对抗路评分标准条件 王者荣耀皮肤山海奇都多少钱 王者山海奇都皮肤价格 王者七夕发福利,公孙离狐妖联动皮肤,只需88碎片兑换 新机遇、新体验、新服务,HarmonyOS 游戏领启未来 鸿蒙游戏亮相ChinaJoy:碰一碰、声控等创新玩法,重构游戏交互边界 彻底颠覆传统电视!华为MateTV首拆:搭载麒麟9020旗舰芯 抖音小号开直播有收益吗?抖音直接开直播能赚钱吗 王者营地如何实现跨区组队 王者荣耀120评分攻略 王者荣耀顶级打野怎么获得 顶级打野评分标准详解 王者荣耀顶级怎么拿 各分路顶级评分标准详解 王者荣耀s40玩哪些英雄上分 s40赛季最好上分的英雄推荐 某轻量云dd安装win7 or win10 如何解绑头像关联账号 续航耐用双灭霸,国民旗舰vivo Y500正式发布! 2025年kpl夏季赛决赛谁打谁 2025年kpl夏季赛决赛谁是冠军 王者荣耀中路法师出装铭文保姆级攻略:嫦娥女娲小乔赢政一网打尽 王者荣耀体验服9.2有什么更新-王者荣耀9月2日体验服更新公告 续航耐用双灭霸,国民旗舰 vivo Y500 正式发布! 租号玩如何收藏账号 7881游戏交易怎么用_7881平台买卖功能使用指南 百度手机助手如何安装游戏 百度手机助手游戏下载指南【详解】 游戏陪玩职业化发展 解锁青年灵活就业新赛道 王者荣耀万象天工开启方法 iPhone情侣模式如何启用双人游戏排行?与伴侣竞技的设置指南以上就是大模型开始打王者荣耀了的详细内容,更多请关注其它相关文章!





发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。